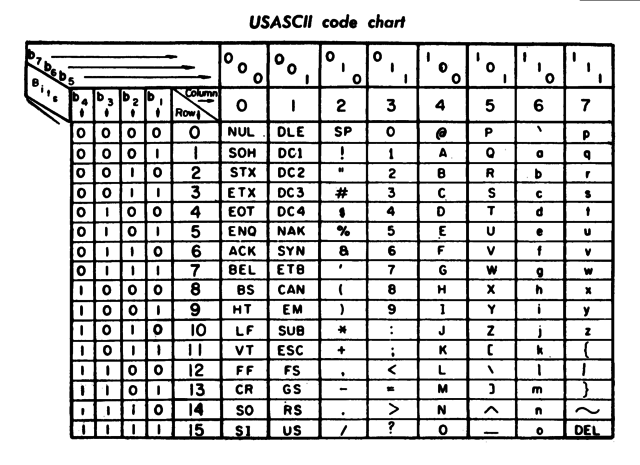
ASCII chart from a 1972 printer manual
On June 17, 1963, the American Standard Code for Information Interchange, or short better known as ASCII code was published as ASA X3.4-1963 by the American National Standards Institute. ASCII codes represent text in computers, communications equipment, and other devices that use text. Most modern character-encoding schemes are based on ASCII, though they support many additional characters. ASCII was the most common character encoding on the World Wide Web until December 2007, when it was surpassed by UTF-8, which is fully backward compatible to ASCII.
Computer Communication Problems
Before the introduction of the ASCII standard, computer manufacturers handled the encoding issue in their own way. This resulted in the problem that different computers were not able to communicate with each other. Further, the manufacturers created their own methods to represent letters, numbers, and so on and around 60 different methods evolved at the time. I.B.M alone had around nine different character sets. For the encoding of Latin characters, EBCDIC, which IBM developed in parallel to ASCII for its system/360, was a serious competitor at that time and is incompatible with ASCII, is used almost exclusively on mainframes. The handling of the alphabet is more difficult in EBCDIC, because it is divided into two separate code areas.[7]
The Character Set
The printable characters include the Latin alphabet in upper and lower case, the ten Arabic digits and some punctuation marks (punctuation marks, word marks) and other special characters. The character set corresponds to a keyboard or typewriter for the English language. The non-printable control characters contain output characters such as line feed or tab characters, log characters such as end of transmission or confirmation, and separators such as data record separators.
Bob Bemer and the Proposal of ASCII
The early efforts to create the ASCII standard were accomplished by Bob Bemer who worked for I.B.M in the 1950s and 1960s. Today, he is referred to as the father of ASCII by many. The actual work on ASCII began in 1961. Bemer submitted a proposal for a common computer code to the American National Standards Institute (ANSI) and the committee called X3.4 representing most computer manufacturers back then and chaired by John Auwaerter was created and began working on the problem.
7-Bit ASCII
In 1963, Bemer and Auwaerter came to an aggreement and ASCII was established. Today, ASCII codes represent text in computers, telecommunications equipment, and other devices. Most modern character-encoding schemes are based on ASCII, although they support many additional characters. Each character is assigned a 7-bit bit pattern. Since each bit can take two values, there are 27 = 128 different bit patterns, which can also be interpreted as the integers 0-127 (hexadecimal 00h-7Fh).
Early Codes
An early form of character encoding was Morse code.[5] It was displaced from the telegraph networks with the introduction of teleprinters and replaced by the Baudot code and Murray code.[6] From 5-bit Murray code to 7-bit ASCII it was only a small step – ASCII was also used for certain American telex models, such as the teletype ASR33. The first ASCII version, still without lowercase letters and with small deviations from today’s ASCII for the control and special characters, was created in 1963. In 1968 the ASCII, which is still valid today, was defined.
8-Bit ASCII and Unicode
To overcome the incompatibilities of national 7-bit variants of ASCII, various manufacturers initially developed their own ASCII-compatible 8-bit codes. In order to meet the requirements of the different languages, Unicode was developed. It uses up to 32 bits per character and could therefore distinguish over four billion different characters, but is limited to about one million permitted code points. This allows all characters previously used by humans to be displayed, provided they have been included in the Unicode standard. UTF-8 is an 8-bit encoding of Unicode that is backwards compatible to ASCII.
Harry Porter, Lecture 12/12: ASCII and Unicode, [8]
References and Further Reading:
- [1] ASCII-World History
- [2] Biography of Bob Bemer
- [3] The History of Character Codes
- [4] ASCII Code at Wikidata
- [5] Dit dit dit da dit – The first Morse Telegram, SciHi Blog
- [6] Émile Baudot and his Telegraph, SciHi Blog
- [7] The IBM System/360 and the Use of Microcode, SciHi Blog
- [8] Harry Porter, Lecture 12/12: ASCII and Unicode, hhp3 @ youtube

